Hey there! I am back again with my overly-complicated way of reviewing what happened in the last year. I recorded my day-to-day using a Google Form in which the records are stored in Google Sheets. Then I exported the data to Jupyter so I can analyse it using Python. You can see the Google Form and the codes on Github. Also, you can check my last year’s attempt with R.
Even though I also reflect weekly, I will only use the Daily Journaling Form to not go over-scope. I only had 44 out of 52 weeks in a year (84%) while in the Daily Journaling, I have 322 out of 365 days in a year (88%). I am considering not making the weekly for next year, but trying something else that is more prospective than retrospective, maybe planning the week ahead instead.
TL;DR I did manage to write 322 entries and did some analyses:
1) Visualising Daily Rating
2) Word Count of Feelings
3) Cleaning Text from Stopwords (and trying Stemming using Sastrawi)
4) Clustering the days using k-means and Affinity Propagation
5) Word Cloud


There is a slight delay because I overexerted myself. Going abroad to two different countries in a month made me exhausted. Also, bad lucks happened that I lost my phone by accidentally throwing it in a lake and I am having trouble refunding a car booking that could not be collected. So… trying to have some compassion for myself… this is definitely not a good start to doing something complex. After some days of procrastinating due to the fear of not being perfect, I made it! It is not perfect.
This one won’t be analysis-heavy, but more about practising the new-found Python coding skill I gained during my graduate study. After finishing the Foundations of Computing course which forced us to not use any additional library, this felt like breathing fresh air, I could just copy-paste things from the internet 😀 (Thanks to kind strangers who built the libraries and those who put their codes up for newbies like me!)
Okay, here we go! The meat of this blog. The Analysis! I did some of the similar things I have done in for last year’s EoY Review, while also doing additional steps to make it looks more sophisticated (so I can learn more stuffs).
Daily Rating
Visualising the daily rating
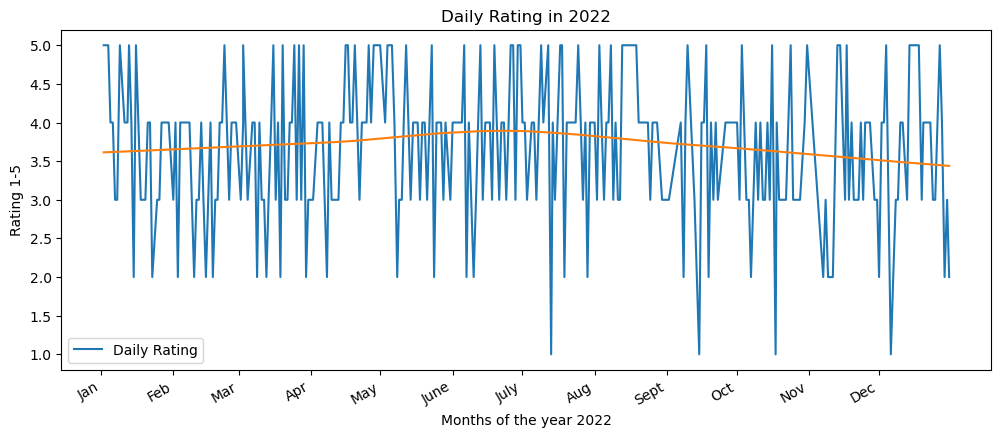
Almost every day, I rated my days from 1 (very bad) to 5 (very good). I know I will lose some details in a day by doing that, but in the end, the way we reflected on our days influences our satisfaction too. I want to be able to rate my days as good even when shits happened, especially because there will be more shits that will happen in the future 🙂
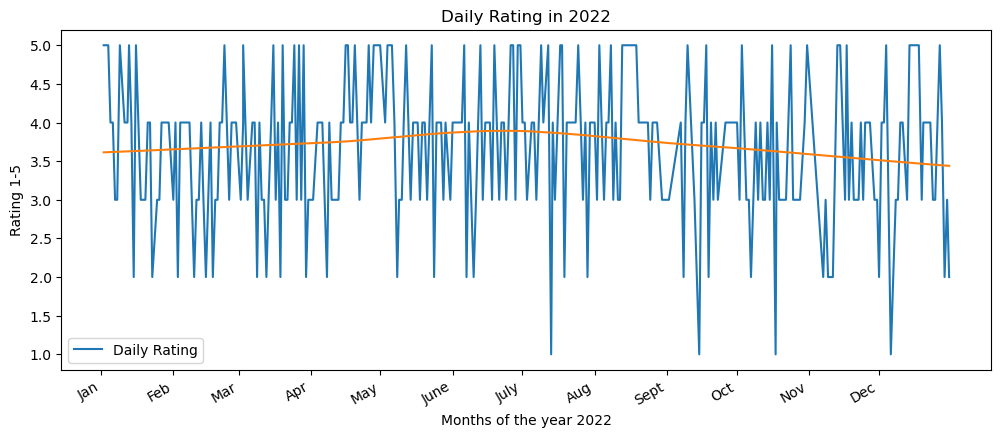
I love to do this one. Even though, ggplot in R gives a more beautiful graph compared to matplotlib in Python, this still gives me a sense that day-to-day feelings fluctuate a lot. I am happy to know that when I smoothen the graph using loess method, it never reaches below 3. Yay! I was pretty good in general this year.
Additional step:
Finding out the feelings experienced the most during best and worst days
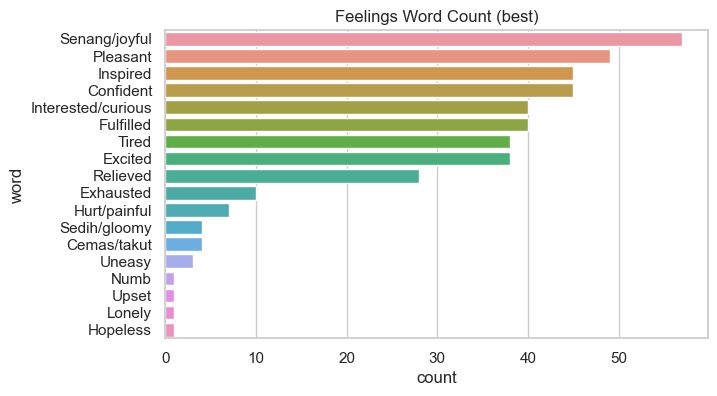
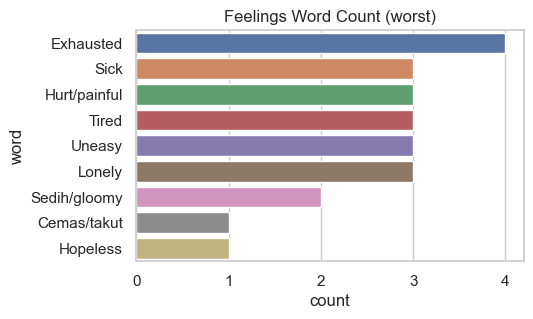
I also had a checkbox to indicate what I felt during the days. Instead of correlating the feelings, I only counted the occurrences of the feelings that I experienced during the best days (days that I rated as 5) and worst days (days that I rated as 1).


Insight: Finding out that I was tired most of the time
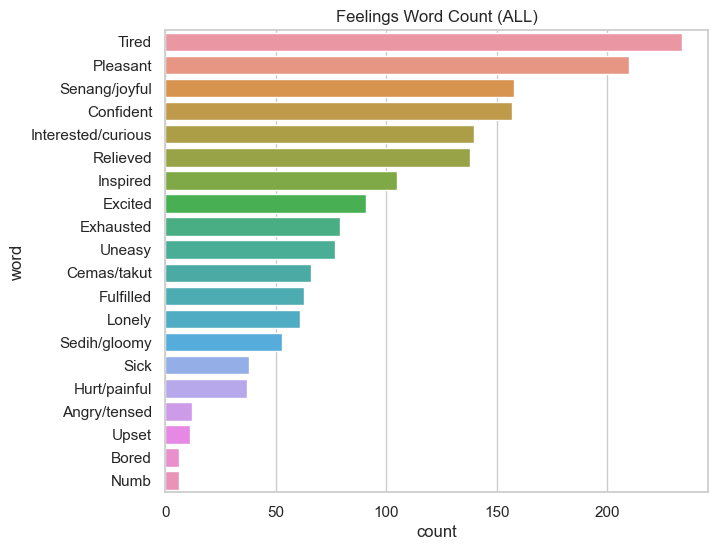
Tired is again the most experienced feeling all time, it’s the same as last year’s. The more I think of it, I guess that’s because I usually filled the form at the end of the day, being already tired, but not wanting to give up on having consistency in filling the form. I guess we have a trade-off of data quality, between “experiencing the day as complete as I can” and “not being affected by being tired at the end of the day”. I think I can fill in the daily journaling the day after and recall yesterday’s events instead. Since my goal is to be able to recall things in a slightly rosy-manner and not to accurately report all the events that happened that will work. My smart watch already does the latter anyway, I guess. LOL.
In general, I have 61 best days (rated 5) and 4 worst days (rated 1). Happy, pleasant, inspired for the best days and exhausted, sick, hurt/painful for the worst days.
Cleaning the text for further analysis
Removing stop words (using nltk library)
Removing the stopwords from the notes column and then tokenising them. This is similar to the previous year’s analysis. I did modify some of the words based on my new understanding of what makes a sentence meaningful.
Snippets of the stop words 
Using nltk library to tokenize and count the words
Additional step: stemming the words (not useful)
I also tried to do stemming of the words. This means removing the letters and returning them into their basic form. I just knew that in my native language (bahasa Indonesia), we do have the stemming library called Sastrawi. However, after trying that, it turned out that this does not make my analysis more meaningful. Maybe that’s because I also mix English in my journal entries. Another LOL.
New stuff: Clustering the notes
K-means clustering
Maybe… I can do something new too? I like the idea of clustering. It simplifies complex stuffs into a more digestible stuff. Using the notes on each day, I tried to see different kinds of days that I experienced.
Thanks to a friend of my friend on Discord that suggested the idea to add a title for every day, I started doing that since the middle of the year (June 4th, to be exact). This will be useful in my clustering effort.
Firstly, I used k-means clustering. The algorithm requires me to set the number of clusters beforehand. It used the tokens of words (words from the notes column that has been cleaned from punctuations and stop words). I plugged in either 3 or 4 clusters with ngram range of either 1-2 or 2-3 until I get a proportional distribution of clusters. I decided that 4 clusters with ngram of 2-3 words is the best.


There are 4 types of days during the year:
- Cluster 1 is about self-improvement (‘diri sendiri’, ‘bisa lebih’)
- Cluster 2 is about having good days in the early 2022 where I wasn’t putting the titles
- Cluster 3 is about feeling accomplished after achievements (‘seneng bisa’, ‘udah bisa’)
- Cluster 4 is about wishing to achieve something (‘semoga bisa’, ‘bisa dapet’)
Where are these clusters within the timespan?
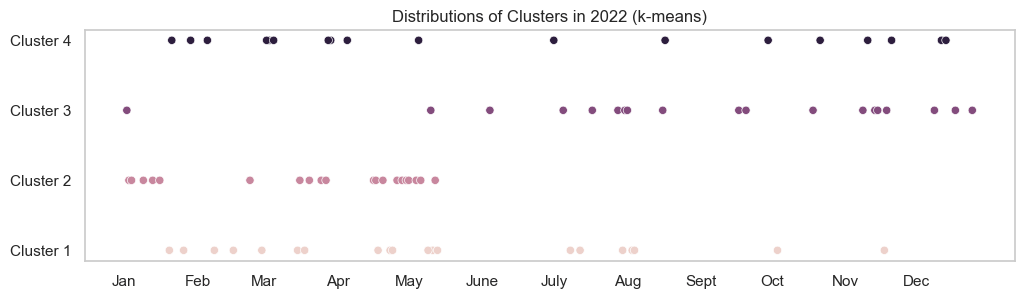
Looking at the plot, maybe I was that different in the first-half of the year. Maybe that’s because I had more time on my hands to do more reflective stuffs. I feel like I was being super busy. But I got busier only starting from Q3 because of my study, not since June. So, maybe that’s because by putting a title on the day, the way I reflected on my days becomes different. I am not sure, but I think this explanation may be less wrong. I then tried to do k-means clustering but with Cosine Similarity, but it did not show any difference.
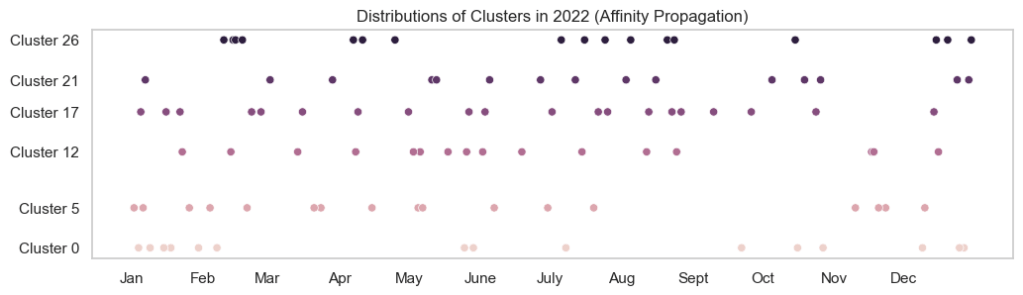
Other clustering method: Affinity Propagation
I also did Affinity Propagation, an algorithm that does not require a predefined number of clusters. It does an iterative process of passing the message between a pair of data points until it achieves convergence. Analogous to centroids from k-means, there is this thing called exemplars, which keeps being updated until the final ones are representative of each cluster. You can read more about it in the book.
“AP creates these clusters from the data points by passing messages between pairs of data points until convergence is achieved. The entire dataset is then represented by a small number of exemplars, which act as representatives for samples. These exemplars are analogous to the centroids that you obtain from k-means or k-medoids. The messages sent between pairs represent how suitable one of the points might be, in being the exemplar or representative of the other data point. This keeps getting updated in every iteration until convergence is achieved with the final exemplars being the representatives of each cluster.”
excerpt from Text Similarity and Clustering by Sarkar (2019)
I got top 6 clusters with varying titles. I think the first one (Cluster #17) is about positive experiences where I did not write much. Maybe when I am happier, I become less reflective. The second cluster (Cluster #5) has more words in the notes. While the third one has about (#26) three to five-liners. Hmm.. not much of usefulness here, unless I have time to dig further into the notes.

Cluster 0 
Cluster 12 
Cluster 17 
Cluster 21 
Cluster 26 
Cluster 5
I will just stick to the K-means, instead. From the book, it’s also said that it is better to build topic model first for each cluster to have a better representation of them.
Where are these clusters within the timespan?


Word cloud
To conclude this stuffs, I end this with a word-cloud (but now masked with the letter 2022 for fancier viz). Yay. Not my very best effort that I am super proud of, but I still have assignments to do! ); I just need to get this done… hahaha why did I treat this project like my campus assignment?

Reflection
The insights I gained are that this year I accomplished a lot of things, feeling happier in general, and am now able to do Python programming. I also need to revise the Google Form if I want them to be meaningful. Well, the act of writing down my thoughts itself is already affecting me, even when it is hard to quantify.
To be honest, my reflection during this Kafkaesque endeavour is that, “huh, maybe that’s why sometimes in the business process, research can be secondary.” Before doing this lengthy analysis, I did a more-qualitative reflection to reorient myself and create my 2023 resolutions. I think it is more insightful compared to this time-consuming effort. This is saddening due to the fact that I worked as a researcher in a company. (The existensial-crisis begins)
But let’s ask again: “Why?” and “How so?”
I think it is because I did not have specific research questions in mind before doing the analysis. You get what you look for. I just browsed the internet for some easy-to-follow recipes to do some Python “wizardry” to look cool. There are even data that’s not being analysed due to time constraints (I need to finish this, lest I won’t have enough time for my real assignments). Maybe this is because my intention was to “practice my Python skills” instead of to “gain something meaningful out of my journaling text.”
Welp, maybe this is what growing up means: being able to handle contradictions. Having the experience of working as a researcher, learning all the difficult ways to crunch and analyse data, and at the same time discarding the output because it was not useful despite the effort spent and part of my identity as a researcher. Wow. You did grow up, that’s cool.
Well, at least I improved in terms of trying. I tried more stuff and was disappointed more by the efforts. Yet, I am still pretty excited about new things to learn. To be fair, I did not feel the same angst as the previous year when doing this EoY Review. Maybe my brain gained more neuron connections related to programming and data science now, so this feels slightly easier.
For the next year, I am planning to simplify the Google Form to contain more open-ended questions since I already acquired the skill to slice the text and analyse them. Hopefully, I can be more expressive by having less constraint in what I will journal.
Coda
If you are up to doing some journaling this year, my only advice is “don’t be too hard on yourself.” The act of reflecting on the past year is supposed to be useful for your own sake, which can be starkly different to mine. This type of analysis is masochist at its best, but useful for people who need to trap themselves into a situation that they cannot escape in order to learn something (read: me).

What worked for me was putting the link to the form with a link shortener (bit.ly/…) so I can just type in the shortened link whenever I want to journal and you can just access it through one click because the auto-complete will work better compared to a lengthy web address. Maybe you can try this out!
The Google Form copy and the Python codes are up on Github. Feel free to use and modify it according to your own needs. Thanks for reading until the end. I mean it. If you feel like we can be friends, feel free to HMU! Especially if you have a niche interest and no one to discuss it with, I’d be more than happy to be a ‘rubber duck’ to talk to.
Have a good 2023! Let’s try things out more and be a little more disappointed by them, but of course, with more things to learn 🙂
Bonus: a personal attack from a book that I read:

Oh, just recently, I found an actual personal attack from the author of a book that I like: (so let’s not overcomplicate things hahaha)

Leave a comment